安装油猴
https://www.cnblogs.com/jimisun/p/17147731.html
下载并修改脚本
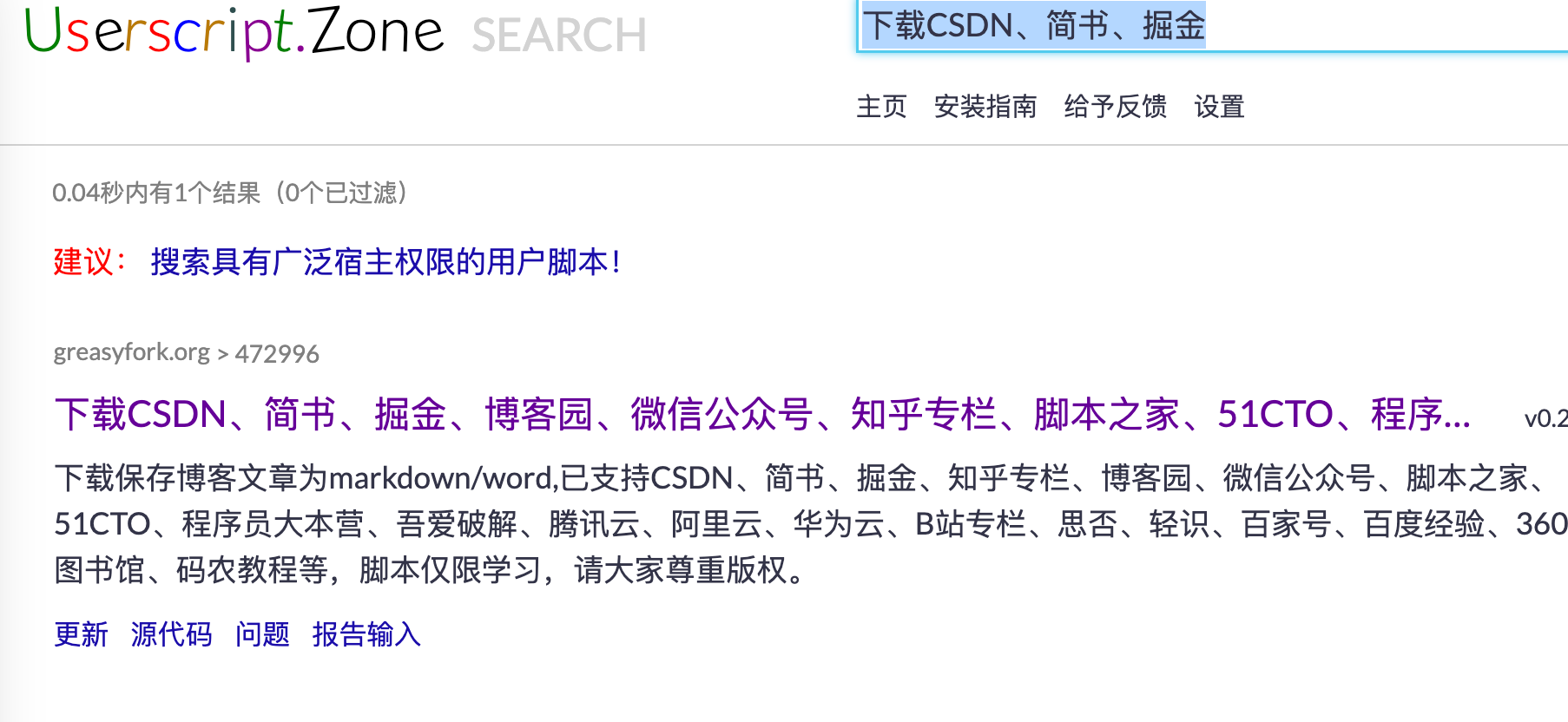
安装好了之后,修改代码
大概文件头的位置
然后就可以正常下载了
延伸
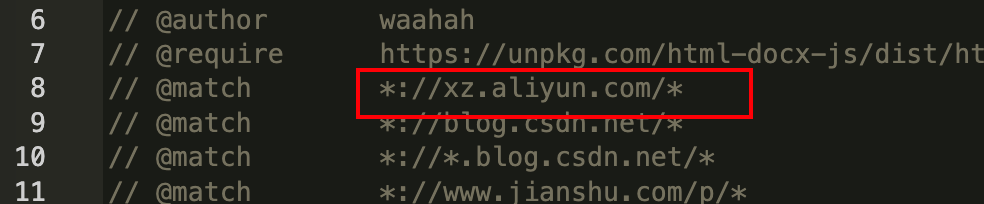
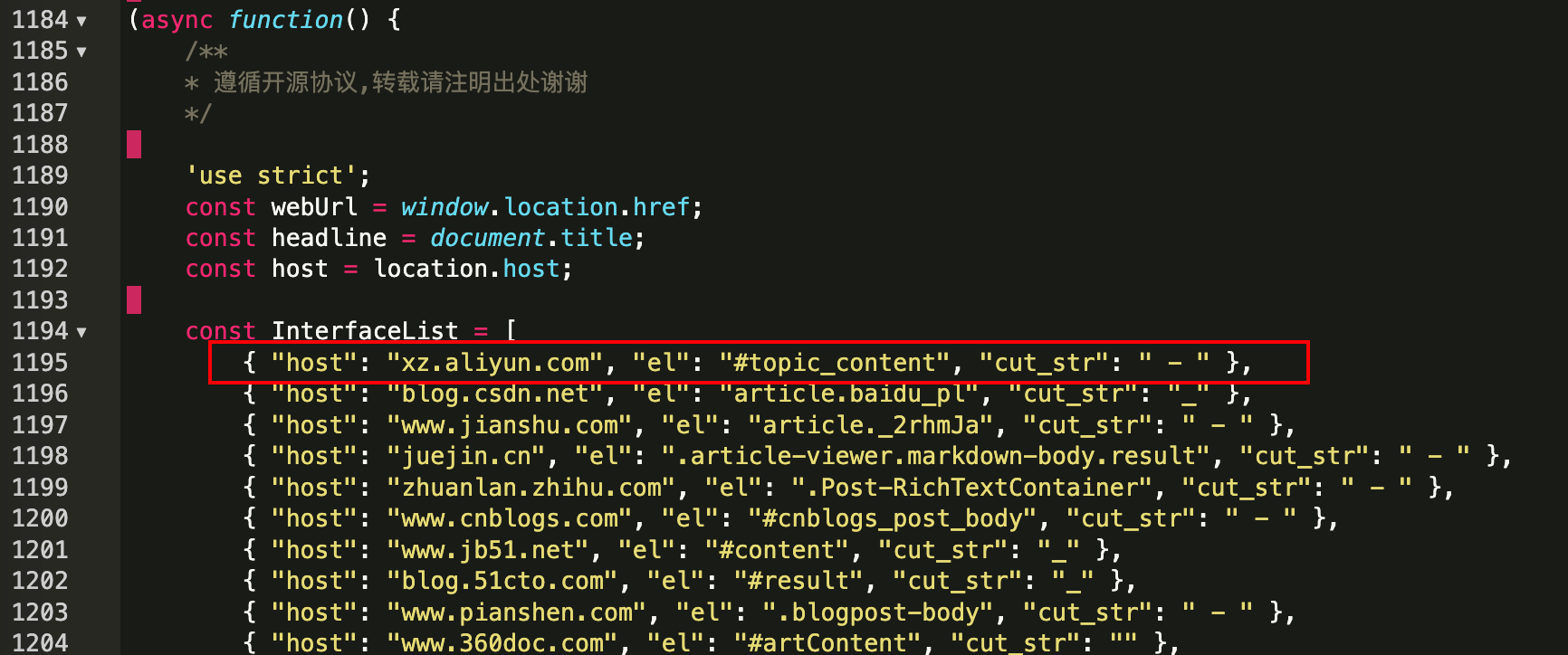
el字段中的字符为 文章对应的 div的id;前提是不是动态加载的

照理说,只要能找到文章存储的标签,任何文章都能下载
比如csdn中的标签为
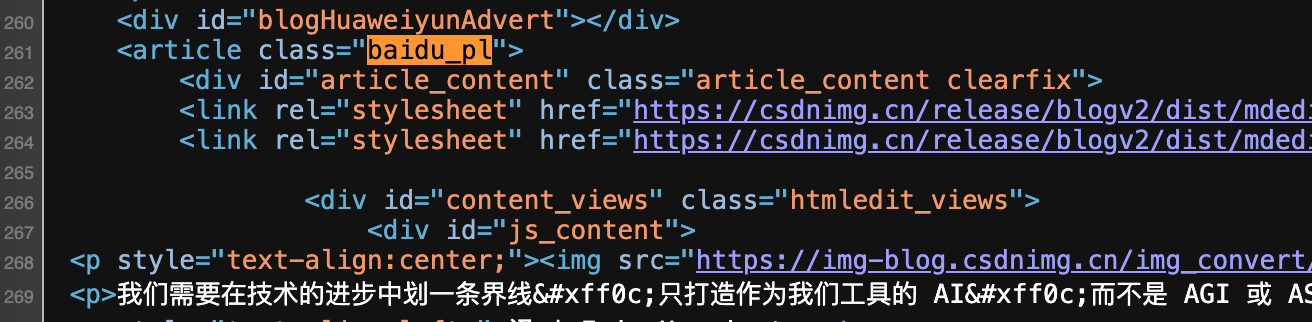
那么在InterfaceList中的el就应该为article.baidu_pl
比如知乎专栏中的文章在<div class="Post-RichTextContainer"> ,
那么规则就应该为 .Post-RichTextContainer
比如51cto的在

那么他的规则就为 #result
比如cnblogs的标签在
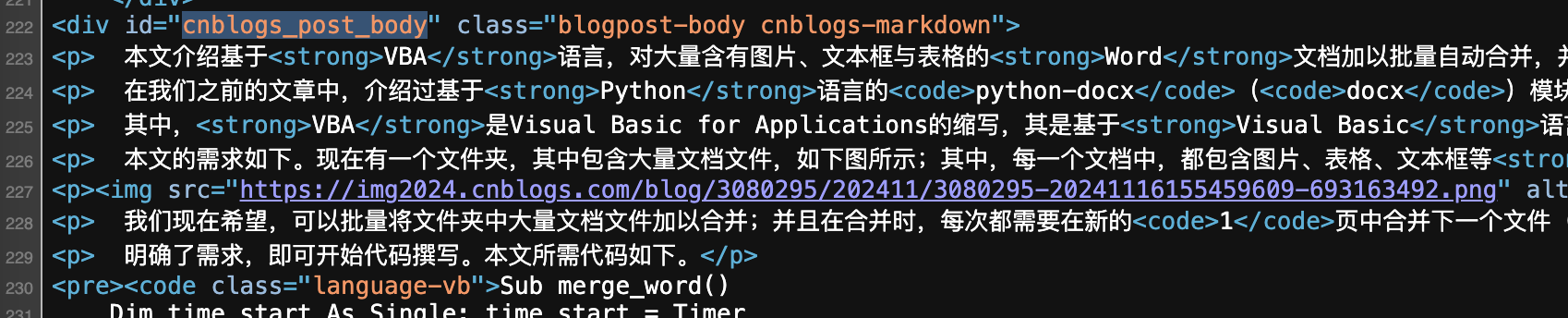
那么规则就为#cnblogs_post_body
那么可以给出添加的一个技巧
- 如果是通过单个class查找文章,el规则为
.className - 如果是通过单个id查找文章,el规则为
#idName <article class="article fmt article-content ">className中含有空格的,用点来代替,.article.fmt.article-content
具体的规则可以查看这篇官方API文档